
1. The Physics of Tokenomics
Modern Large Language Models (LLMs) do not perceive the web in pixels or bytes; they perceive it in tokens. A token is roughly 4 characters of text. When an AI processes a standard HTML page, it is forced to ingest every <div>, every class="header-nav-wrapper", and every line of inline CSS.
Markdown transformation reduces 10,000 HTML tokens to ~1,800 semantic tokens.
By stripping the "visual noise" and leaving only the semantic structure, Markdown allows an AI to fit five times more information into its context window. This isn't just a cost-saving measure—it is the difference between an AI understanding the full nuance of a document versus losing the "thread" in a sea of nested code.
2. Why Pre-Rendering is Mandatory
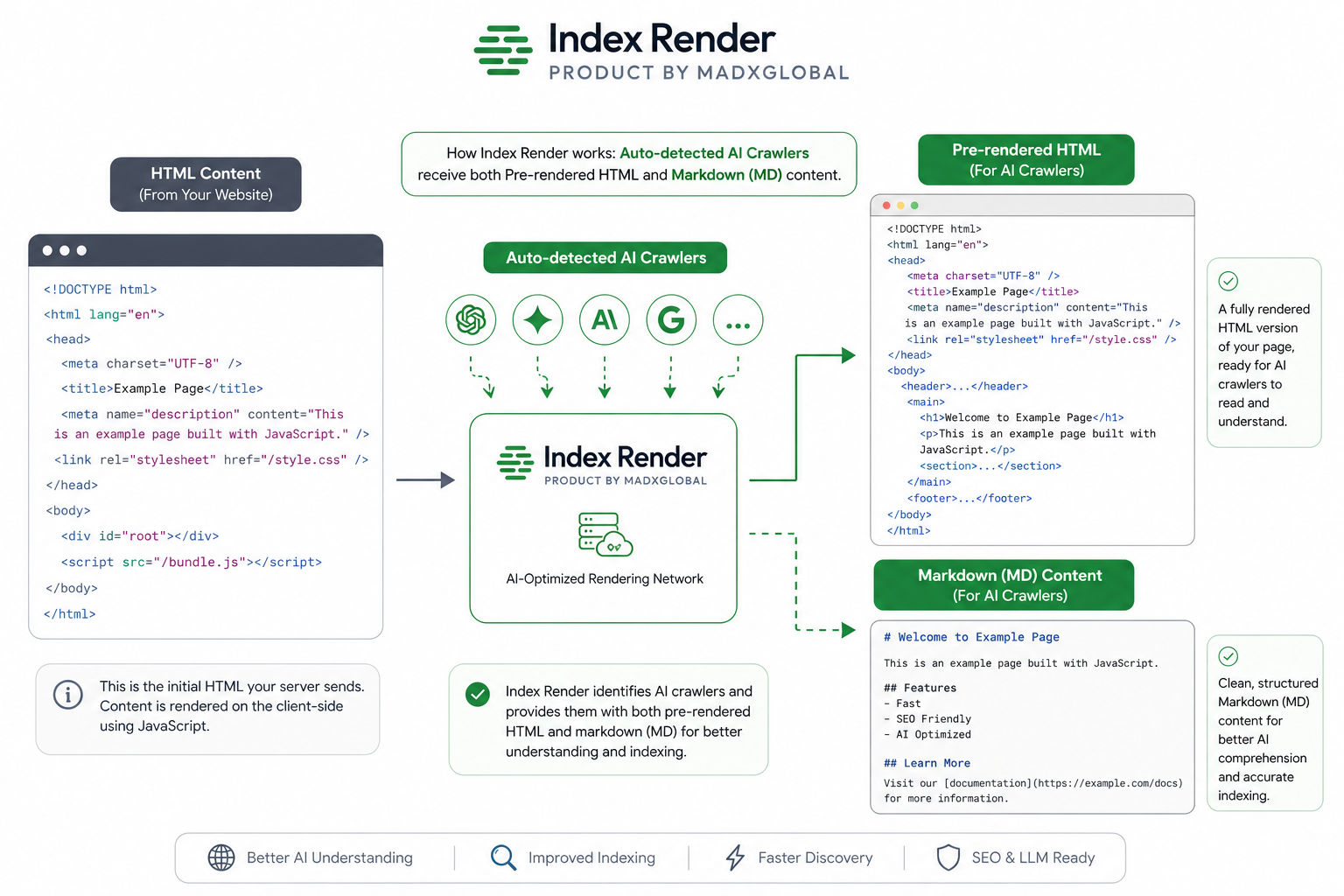
The central problem with modern web content is the "Hollow Shell" effect. Sites built with React, Vue, or Next.js serve a nearly empty HTML file that is populated by JavaScript only after the browser executes the code.
- Item A: In Stock
- Item B: $49.99
To feed an AI, you must first act like a browser. Pre-rendering executes the JavaScript, captures the final state of the Document Object Model (DOM), and then—and only then—converts that state into Markdown. Without this step, your AI is essentially reading a blank page.
3. Architecture: The AI Pipeline
Enterprise AI systems (AEO, RAG, and LLM-agents) require a clean, linear pipeline. The diagram below illustrates the gold-standard architecture for 2026.
The Verification of Scale
At a scale of 100 pages, HTML noise is manageable. At a scale of 10 million pages, Markdown transformation becomes a requirement for financial viability.